
About me
📰 Welcome to My Website!
I’m Divyanshu Mishra, a PhD student in the Department of Engineering Science at the University of Oxford, where I am fortunate to be supervised by Professor Alison Noble and fully funded by the Athena-Bronze Scholarship.
My research centers on long video understanding, with a focus on video localization, self-supervised video representation learning, and multi-modal large language models. Much of my recent work develops these methods in the context of fetal ultrasound imaging for congenital heart disease detection, where I aim to build algorithms that streamline clinical workflows and support clinicians in making earlier and more accurate diagnoses.
Most recently, I interned at Amazon Science as an Applied Scientist 2, where I worked on Video Large Language Models (Video-LLMs) and developed training methodologies that leverage single-modality data to reduce reliance on paired datasets.
Prior to my PhD, I worked as a Data Scientist at the Translational Health Science and Technology Institute (THSTI), Government of India, under the guidance of Prof. Shinjini Bhatnagar. There, I developed machine learning algorithms for a range of challenges in maternal and child health, including preterm birth detection, gestational age prediction, and neonatal outcome assessment. This role gave me valuable experience working closely with clinicians and public health experts to design machine learning tools for practical use in healthcare.
While many of my projects have focused on medical applications, my broader research interests span video understanding, self-supervised learning, and large multi-modal models, with the goal of advancing both foundational methods and their real-world impact across domains.
Feel free to explore my website to learn more about my projects, publications, and ongoing work. I am always open to new collaborations and ideas. Please get in touch if you’re interested in connecting!
📰 News & Achievements
📚 Publications
- Video Anomaly Detection & Model Merging
STUD + DiVMerge – Self-supervised Normality Learning and Divergence Vector-guided Model Merging for Zero-shot CHD Detection in Fetal Ultrasound Videos
Links: ArXiv
- Representation Learning
HarmonicEchoNet – Leveraging harmonic convolutions for automated standard plane detection in fetal heart ultrasound videos. Links: Journal
- Video Understanding
TIER-LOC: Visual Query-based Video Clip Localization in Fetal Ultrasound Videos with a Multi-Tier Transformer
Proceedings: Read it here
- Video Understanding and Model Merging
Self-supervised Normality Learning and Divergence Vector-guided Model Merging for Zero-shot Congenital Heart Disease Detection in Fetal Ultrasound Videos
Proceedings: Read it here
- Federated Learning
F3OCUS – Federated Finetuning of Vision-Language Foundation Models with Optimal Client Layer Updating Strategy via Multi-objective Meta-Heuristics
Proceedings: Read it here
🎓 Academic & Professional
Selected as an Applied Scientist to work on Video-LLMs, focusing on training methodologies using single-modality to reduce dependency on paired data.
Delivered a talk at the Synthetic Data for Machine Learning conference organized by The British Machine Vision Association and Society for Computer Vision.
Selected Publications
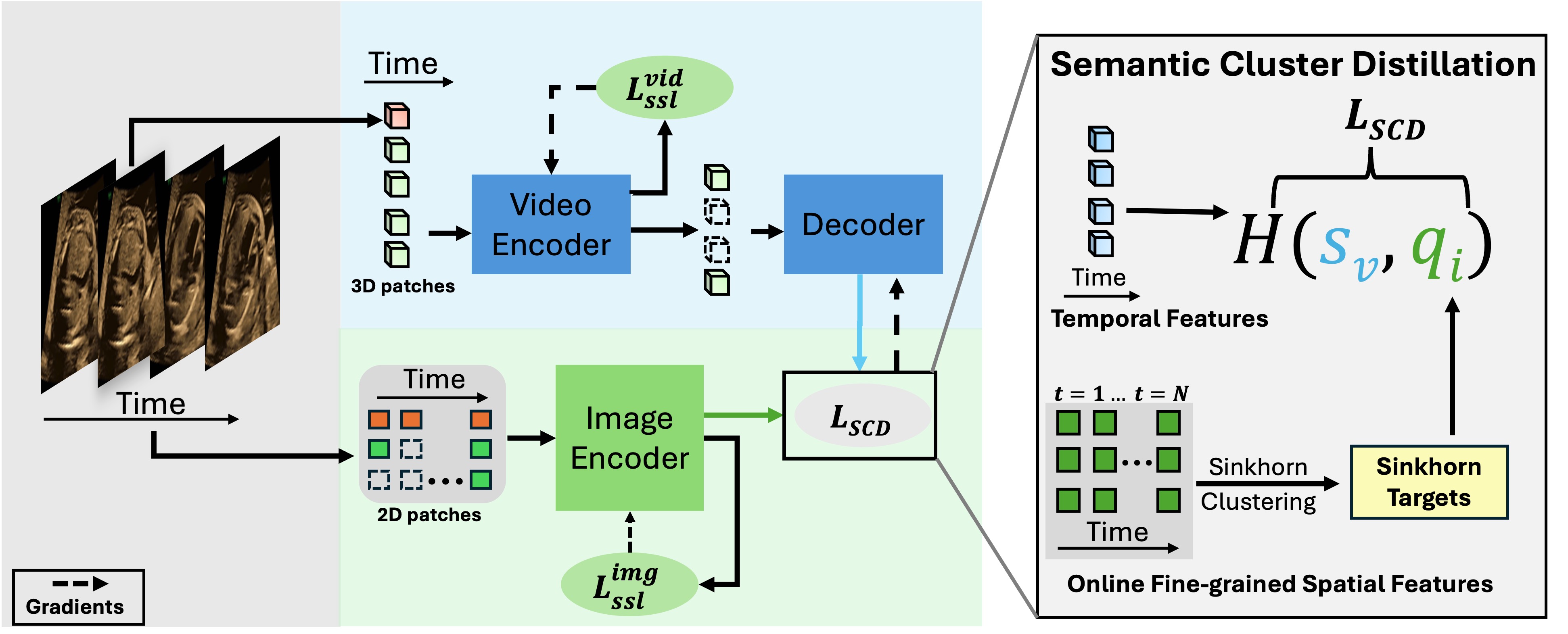
DISCOVR: Self-supervised Learning of Echocardiographic Video Representations via Online Cluster Distillation
A dual-branch SSL framework that aligns a clustering-based video encoder with an online image encoder via semantic cluster distillation, yielding spatially rich and temporally coherent representations for cardiac ultrasound.
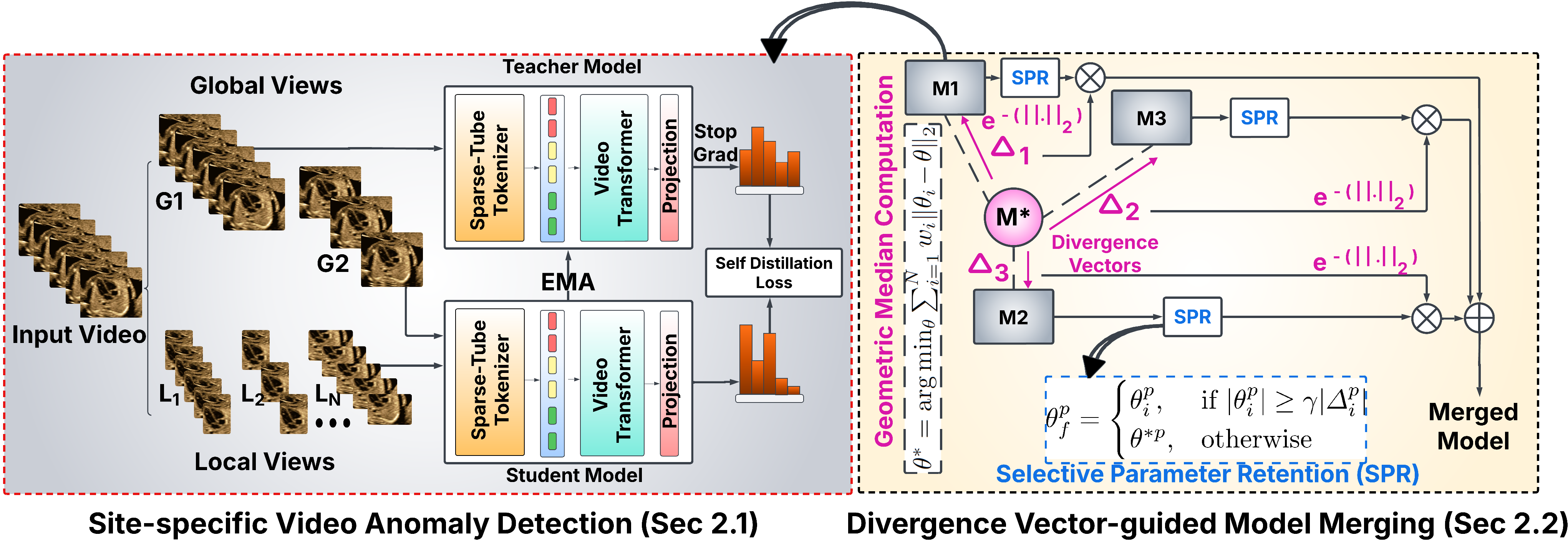
STUD + DiVMerge: Self-supervised Normality Learning and Divergence Vector-guided Model Merging for Zero-shot CHD Detection in Fetal Ultrasound Videos
Each site trains a sparse-tube SSL anomaly detector on normal fetal heart videos; models are merged privacy-preservingly via divergence-vector-guided selection and weighting, enabling zero-shot detection of multiple CHD types.
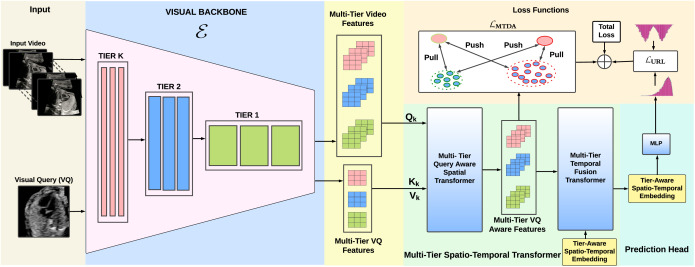
MCAT: Visual Query-Based Localization of Standard Anatomical Clips in Fetal Ultrasound Videos Using Multi-Tier Class-Aware Token Transformer
We introduce the Visual Query-based Video Clip Localization (VQ-VCL) task—retrieving a relevant video clip from a sequence given a query image—and present MCAT, which leverages a multi-tier class-aware token transformer for robust clip localization in fetal ultrasound videos.
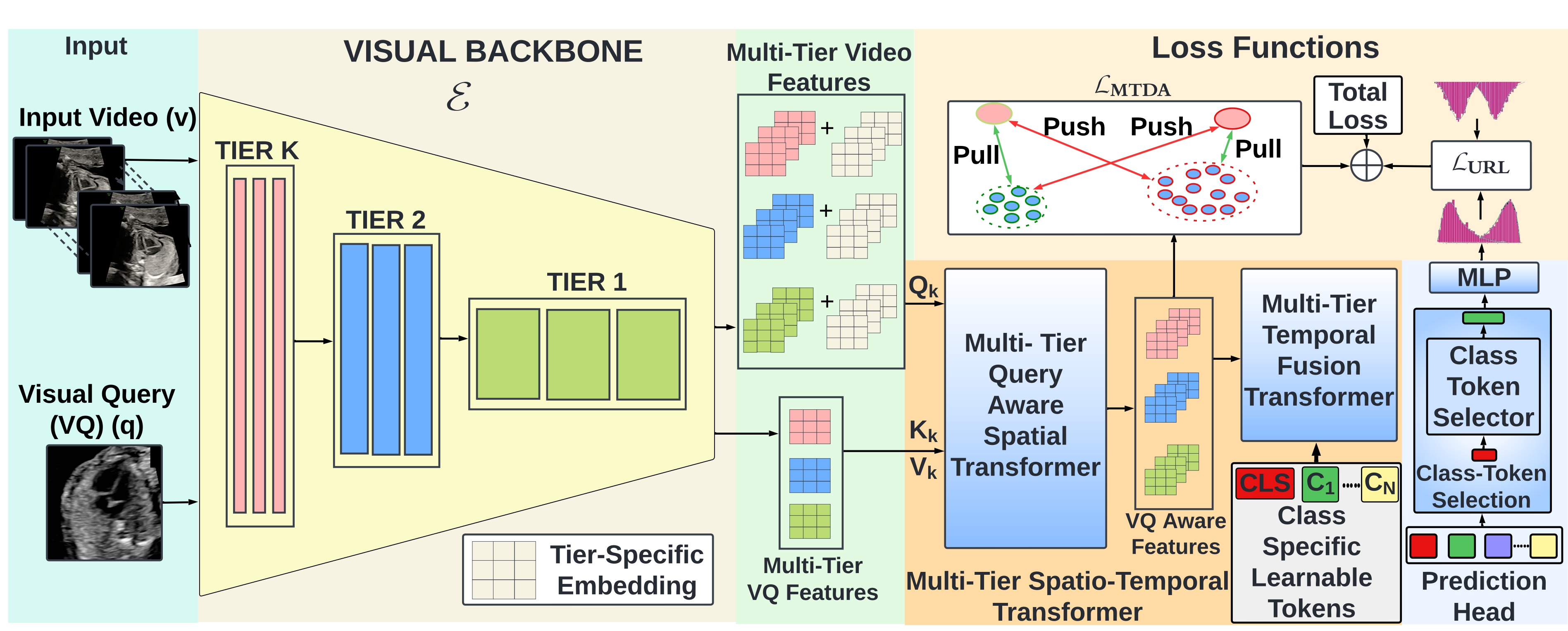
TIER-LOC: Visual Query-based Video Clip Localization in Fetal Ultrasound Videos with a Multi-Tier Transformer
We introduce the Visual Query-based Video Clip Localization (VQ-VCL) task—retrieving a relevant video clip from a sequence given a query image—and present TIER-LOC, which leverages a multi-tier transformer architecture for robust clip localization in fetal ultrasound videos.
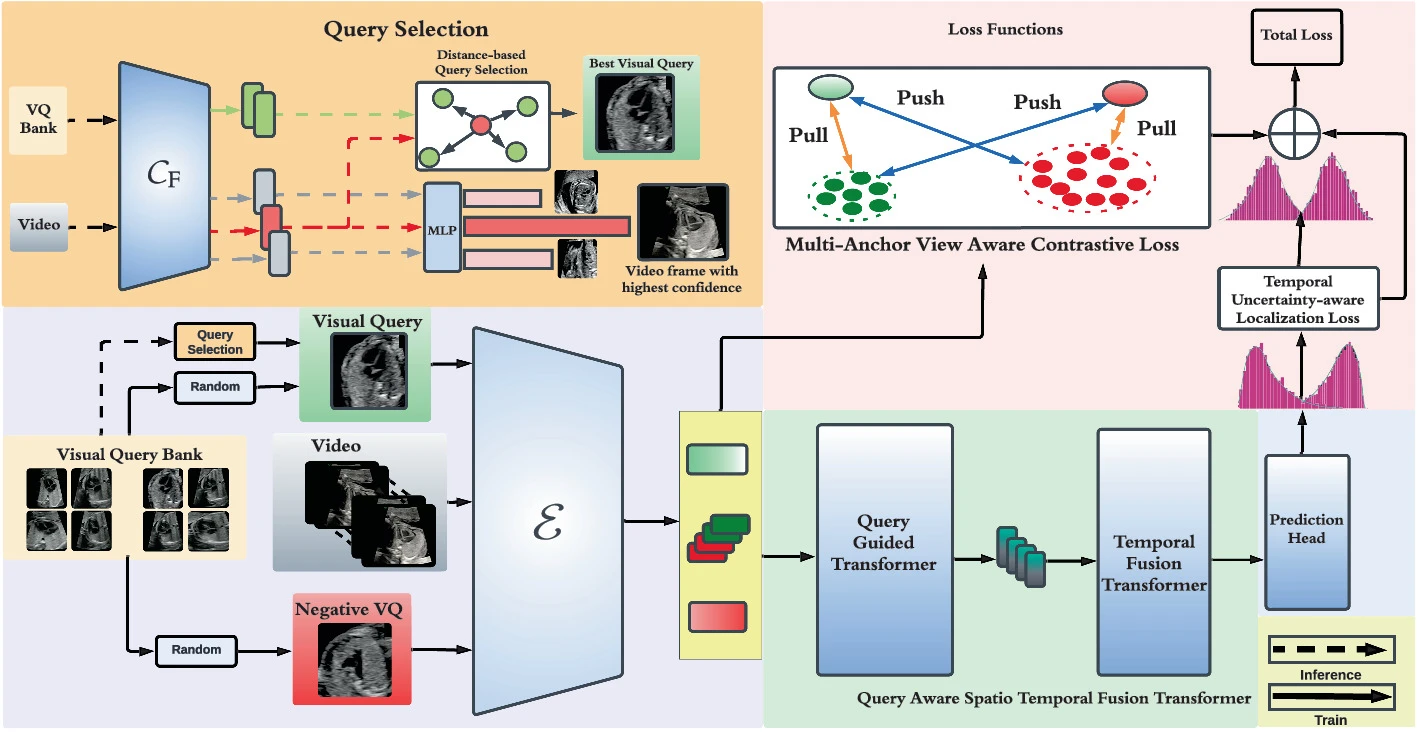
STAN-LOC: Visual Query-Based Video Clip Localization for Fetal Ultrasound Sweep Videos
We introduce the Visual Query-based Video Clip Localization (VQ-VCL) task—retrieving a relevant video clip from a sequence given a query image—and present STAN-LOC, which leverages a query-aware spatio-temporal transformer with multi-anchor contrastive learning for robust clip localization.
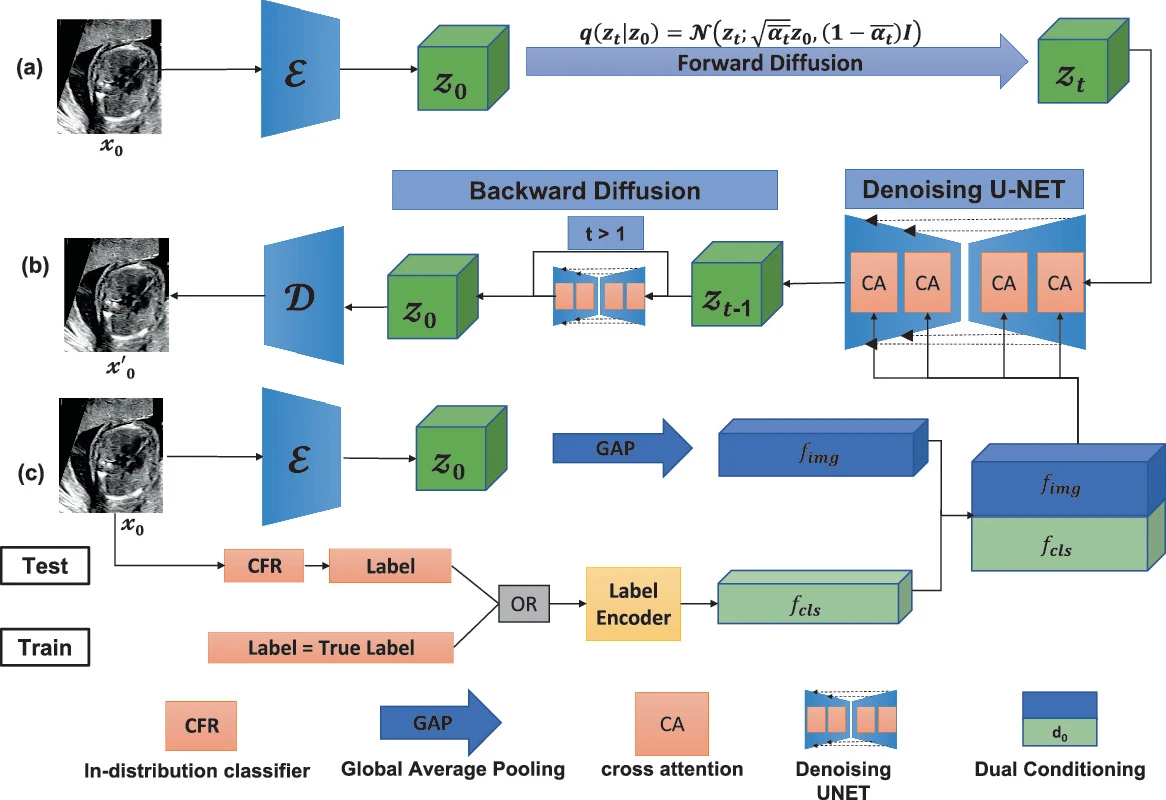
Dual Conditioned Diffusion Models for Out-of-Distribution Detection: Application to Fetal Ultrasound Videos
Out-of-distribution (OOD) detection is essential to improve the reliability of machine learning models by detecting samples that do not belong to the training distribution. We introduce Dual Conditioned Diffusion models (DCDM) to detect OOD samples in Ultrasound videos given we have information only about ID samples during training.